前兩天介紹了資源估計的概念,大概知道了 attention 為什麼有序列長度二次方的關係,那在 inference 怎麼樣去做優化,這就是今天要介紹的。
參考文章&圖片來源:
https://www.cnblogs.com/rossiXYZ/p/18799503
https://zhuanlan.zhihu.com/p/662498827
https://huggingface.co/blog/not-lain/kv-caching (動態圖)
https://medium.com/@joaolages/kv-caching-explained-276520203249 (動態圖)
在前面有提到過自迴歸的模型,當初給了一個類似的圖如下,也就是每次推理會先 concat 上一次的輸出,那現在問題來拉,如果是這樣那到後面長度越長,可想而知一定會越來越慢,所以我們用 kv cache 來。
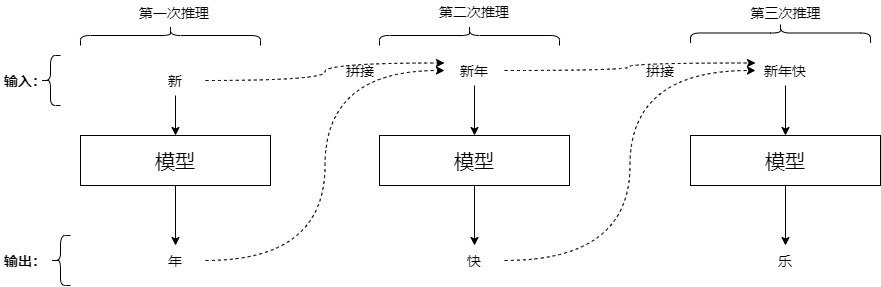
核心觀念: 空間換取時間
簡單概念就是把已經算過的儲存起來,等到下次要用再拿出來,這樣子避免重複計算,就可以讓速度更快,那有哪些是重複計算的呢? 我們用下面幾張圖來講解。
剛才上面的"新年快"分別送進去 model,我們專注於最右邊注意力的部分,你會發現只有最後一個是新計算的,前面都是重複計算,那如果我們將重複計算的部分儲存起來,那不就不用計算了。
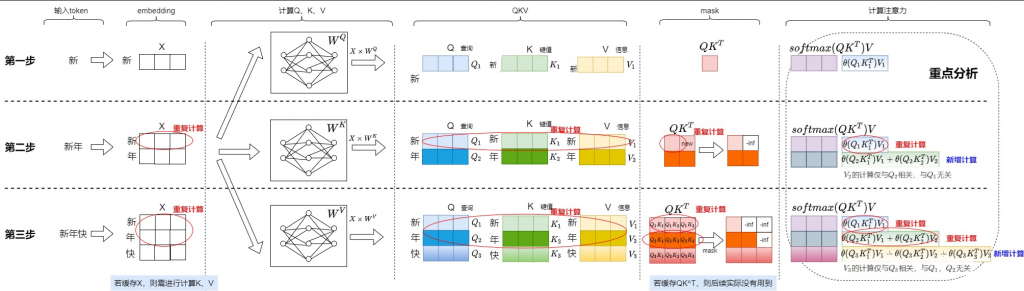
可以上下圖一起看,其中不一樣的點:
如果有 4000 個 token
在沒有 KV Cache 的 QK^T → 長度 4000 的 Q 內積 長度 4000 的 K^T → O(n^2)
有 KV Cache 的 QK^T → 長度 1 的 Q 內積 長度 4000 的 K^T → O(n)
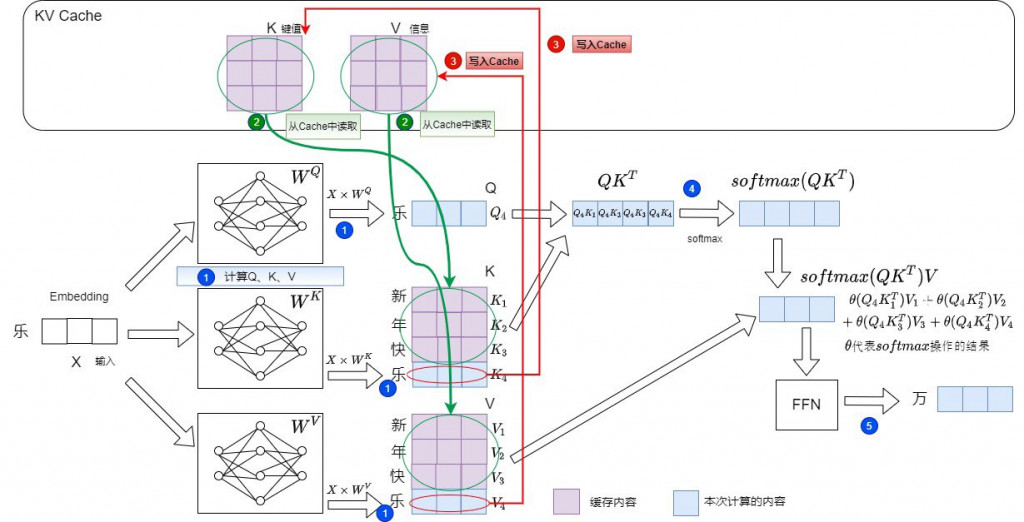
我們用另一張圖來比較有無 kv cache 或者可以參考上面給的第三個連結,當中有動態圖來表示。
每次只需要輸入當下的 Q,然而 kv 會從 cache 拿出先前計算過

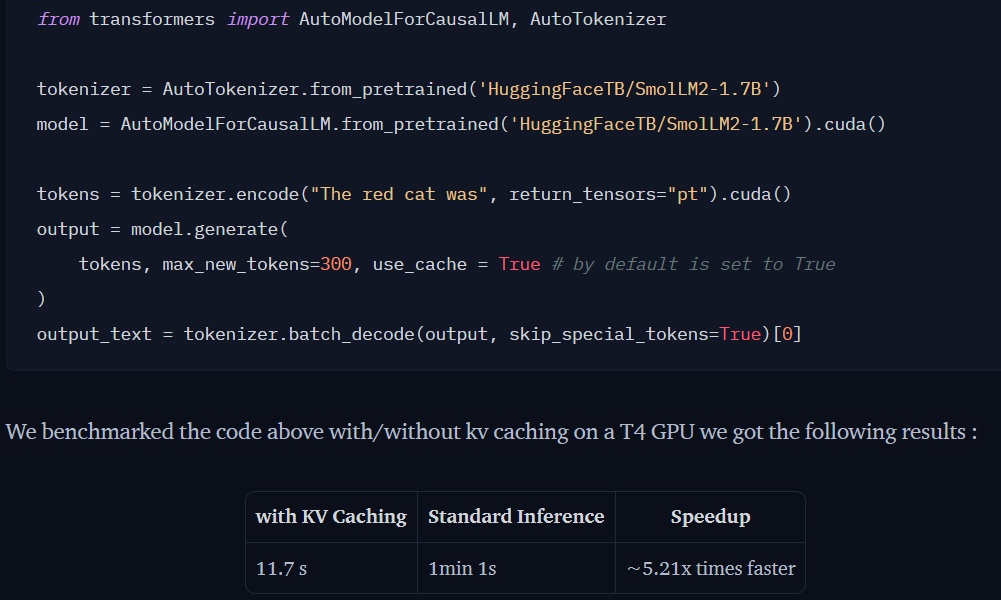
另外來自 huggingface 的測試,比較有無 kv cache
空間換取時間的前提是空間要夠阿,那需要耗費多少記憶體呢? 我們底下來簡單分析一下。
公式: 2×B×L×H×D×PxN
上面可以變的就只有B, L, P,那其中 seq_len 最重要
範例來自於參考文章,所以如果沒有特別去優化的話,你會發現 100K 就需要 22.8GB,

研究著上面的觀念,可以找到一些優化KV cache的具體方向(如下圖):
減少序列長度:保留初始 tokens 或者滑動窗口的 KV
減少注意力頭數:MQA(multi-query attention)、GQA(Grouped-query attention)透過減少 head 個數來減少記憶體佔用。
減少key_bits。轉換成 int8 or int4,來降低每個 token 所需要的 byte。
減少頭維度。 DeepSeekV2 的 MLA 引入了類似 LoRA 的想法,有效地減少了 KV 頭的大小。
優化KV cache 的顯存管理:目前GPU上KV Cache的有效儲存率較低,可以透過類似PagedAttention的方法進行最佳化。 因為不是正交的,我們後續把記憶體管理部分也劃分到」依照特性進行最佳化「部分進行分析。
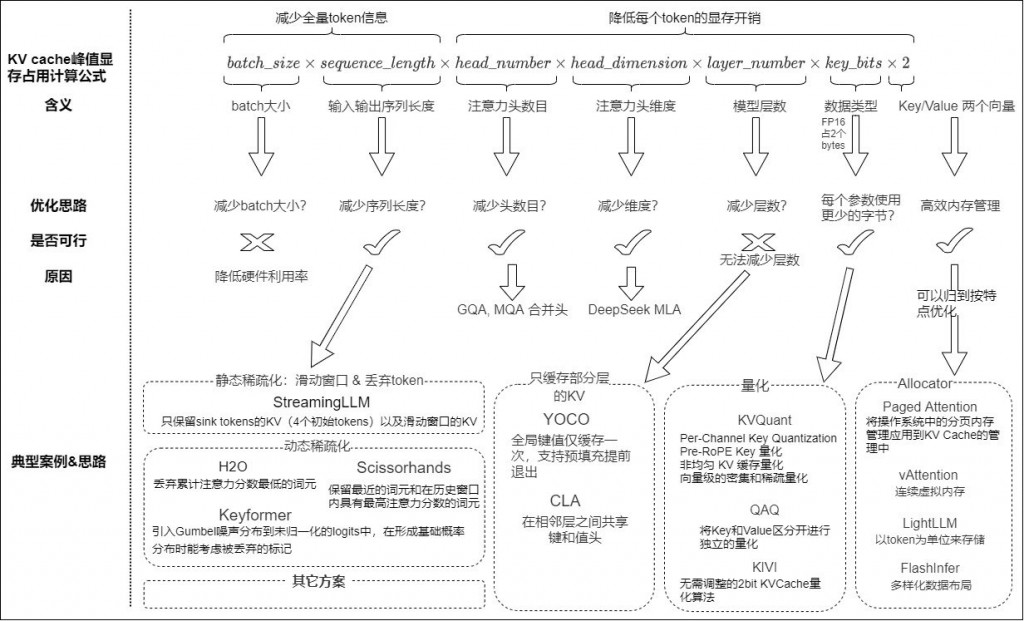
圖片來源: https://www.cnblogs.com/rossiXYZ/p/18811723
今天就先到這裡囉~ 我們明天實際看一個github,就可以知道簡單的 kv cache 其實不難。


 iThome鐵人賽
iThome鐵人賽